Family Photos
Legacy Photos
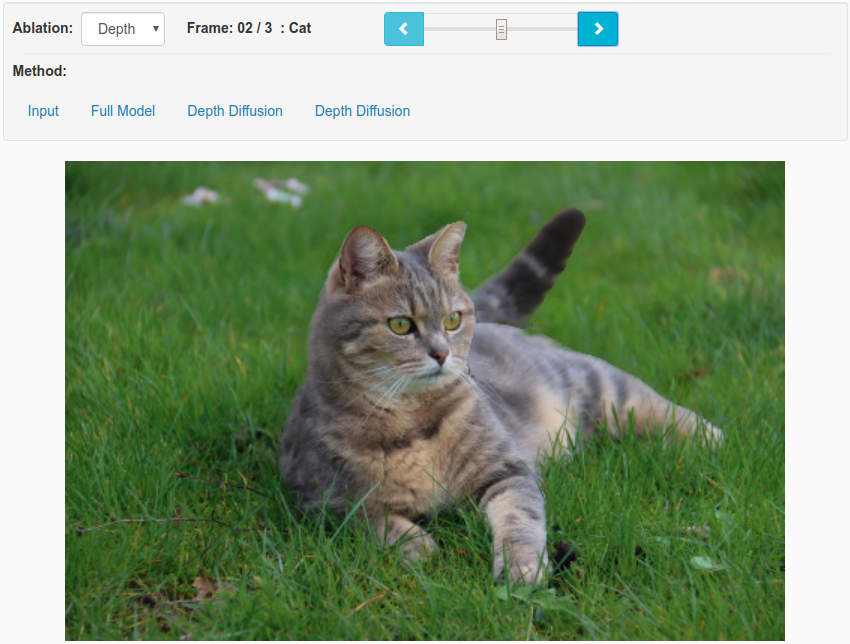
2.5D Parallax Effect
Comparison with State of the art
Dolly Zoom Effect
@inproceedings{Shih3DP20,
author = {Shih, Meng-Li and Su, Shih-Yang and Kopf, Johannes and Huang, Jia-Bin},
title = {3D Photography using Context-aware Layered Depth Inpainting},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}